Quando microserviços viram um monólito pior

O problema que ninguém esperava criar
Você está em uma reunião de retrospectiva. Alguém do time comenta:
"A gente migrou pra microserviços há seis meses, mas parece que ficou mais difícil fazer deploy. Qualquer mudança simples precisa mexer em três serviços diferentes. E se um cai, tudo para."
Outro dev complementa:
"E ninguém sabe mais quem é o dono de qual serviço. Tem código duplicado em todo lugar. E quando tentamos debugar um problema, precisamos subir 8 containers localmente."
O que aconteceu?
O time fez a transição "certa". Leu sobre microserviços, assistiu palestras, estudou cases de sucesso. Dividiu o sistema em serviços menores. Implementou comunicação via HTTP e mensageria. Criou APIs internas.
Mas o resultado não foi um sistema mais simples, mais escalável ou mais resiliente.
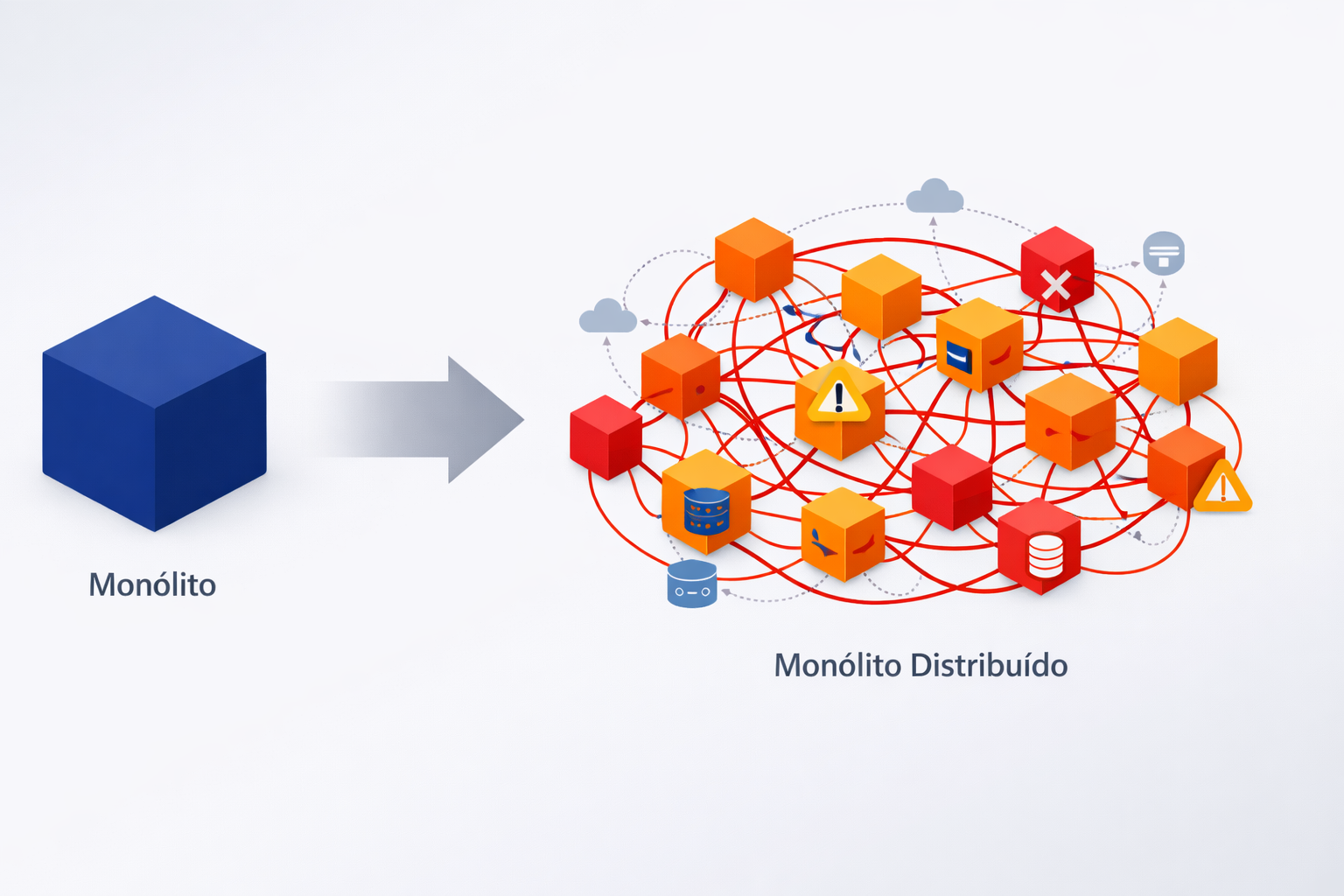
O resultado foi um monólito distribuído — todas as desvantagens de um monólito, somadas à complexidade de sistemas distribuídos.
E o pior: isso não é exceção. É a regra.
O erro de percepção: microserviços não são sobre tecnologia
Quando times decidem migrar para microserviços, a conversa normalmente gira em torno de:
- Vamos usar Docker e Kubernetes
- Cada serviço vai ter seu próprio banco de dados
- Precisamos de um API Gateway
- Vamos usar RabbitMQ pra comunicação assíncrona
Tudo isso está certo. Mas é implementação, não fundamento.
O erro está em achar que microserviços são uma decisão técnica.
Microserviços são uma decisão organizacional.
A pergunta certa não é "como implementamos microserviços?".
A pergunta é: "nosso time e nossa organização estão prontos para lidar com as consequências de ter sistemas distribuídos autônomos?"
Quando a resposta é não, você não ganha microserviços.
Você ganha um monólito distribuído.
O que realmente está acontecendo: acoplamento disfarçado
O monólito distribuído que você criou
Aí veio a "migração pra microserviços". O sistema foi dividido em serviços menores. Mas:
1. Os serviços continuam acoplados
// Serviço de Pedidos
public class PedidoService
{
private readonly HttpClient _clienteApiClient;
private readonly HttpClient _estoqueApiClient;
private readonly HttpClient _pagamentoApiClient;
private readonly HttpClient _notificacaoApiClient; public async Task<Result> CriarPedido(CriarPedidoRequest request)
{
// Valida cliente (chamada síncrona)
var cliente = await _clienteApiClient.GetAsync($"/clientes/{request.ClienteId}");
if (!cliente.IsSuccessStatusCode)
return Result.Fail("Cliente não encontrado"); // Reserva estoque (chamada síncrona)
var estoque = await _estoqueApiClient.PostAsync("/reservas", ...);
if (!estoque.IsSuccessStatusCode)
return Result.Fail("Estoque insuficiente"); // Processa pagamento (chamada síncrona)
var pagamento = await _pagamentoApiClient.PostAsync("/pagamentos", ...);
if (!pagamento.IsSuccessStatusCode)
{
// Precisa desfazer a reserva de estoque
await _estoqueApiClient.DeleteAsync($"/reservas/{reservaId}");
return Result.Fail("Pagamento recusado");
} // Cria o pedido
var pedido = await _pedidoRepository.Create(...); // Envia notificação (chamada síncrona)
await _notificacaoApiClient.PostAsync("/notificacoes", ...); return Result.Ok(pedido);
}
}
O que parece modular na superfície esconde uma verdade brutal:
- 4 chamadas HTTP síncronas para criar um pedido
- Se qualquer serviço cair, o fluxo quebra
- Transações distribuídas implementadas na mão (e mal)
- Rollback manual quando algo falha
- Latência acumulada (4 chamadas em sequência)
Você não ganhou independência. Ganhou dependências via rede.
2. Deploy continua acoplado
Deploy do serviço de Pedidos: - Requer que a versão 2.3 do serviço de Clientes esteja rodando - Incompatível com versão 1.8 do serviço de Pagamento - Precisa subir junto com nova versão do serviço de NotificaçõesResultado: deploy de 4 serviços ao mesmo tempo
Antes você deployava um monólito inteiro.
Agora você faz deploy de 4 serviços "independentes" ao mesmo tempo.
Qual a diferença? Nenhuma. Só ficou mais complexo orquestrar.
3.
4. Dados duplicados em todo lugar
Como cada serviço "precisa ter seu próprio banco", os times começam a duplicar dados:
// Serviço de Pedidos
public class Pedido
{
public int Id { get; set; }
public int ClienteId { get; set; }
public string ClienteNome { get; set; } // Duplicado
public string ClienteEmail { get; set; } // Duplicado
public string ClienteCPF { get; set; } // Duplicado
// ...
}// Serviço de Notificações
public class NotificacaoModel
{
public int ClienteId { get; set; }
public string ClienteNome { get; set; } // Duplicado
public string ClienteEmail { get; set; } // Duplicado
public string ClienteTelefone { get; set; } // Duplicado
}
Por quê? Porque fazer chamadas HTTP pra buscar dados em tempo real é caro e arriscado.
Resultado:
- Dados inconsistentes entre serviços
- Sincronização manual (que sempre falha)
- Lógica de negócio espalhada
5.
Onde times mais erram: as armadilhas invisíveis
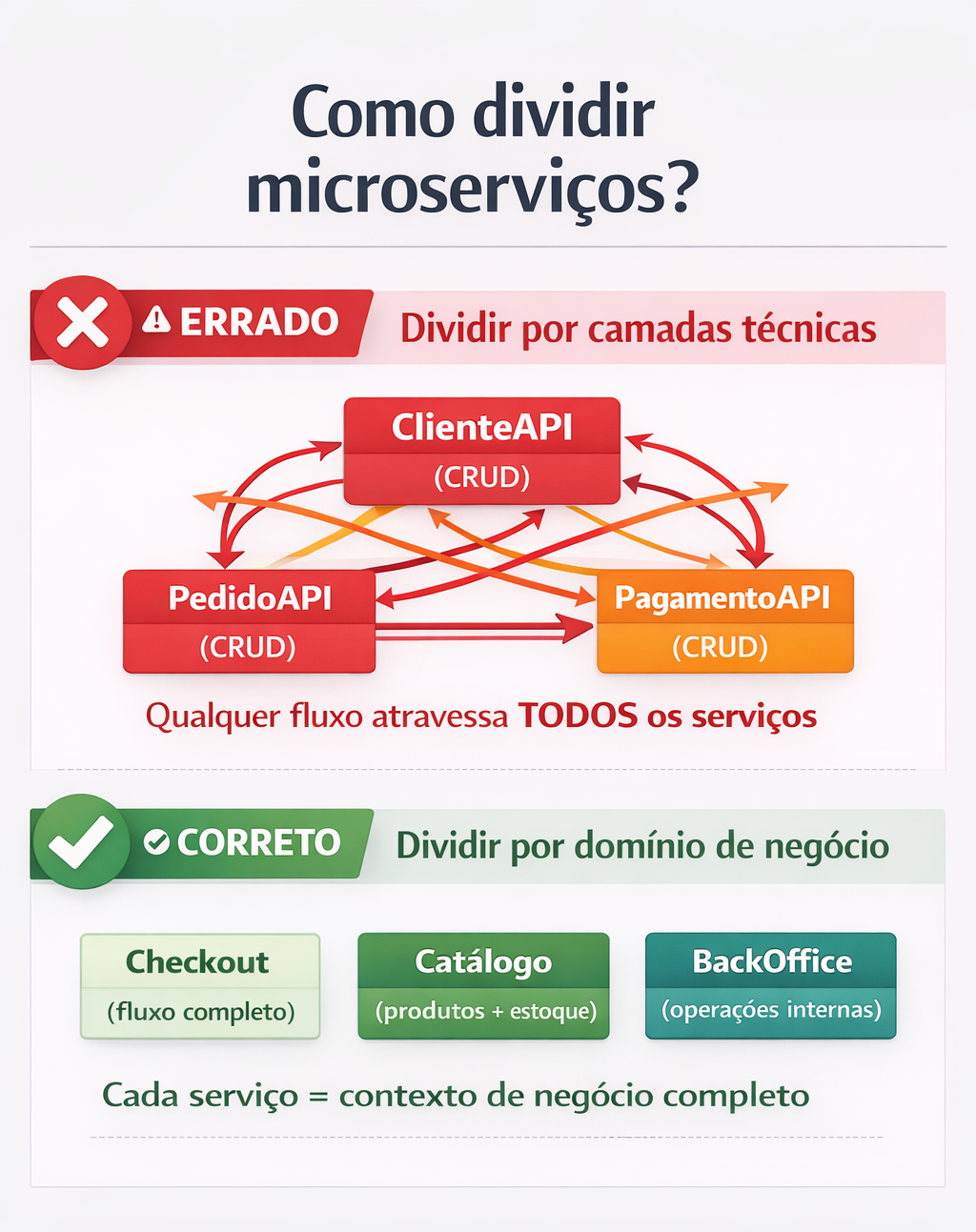
1.

2. Comunicação síncrona entre todos os serviços
Se você tem uma cadeia de chamadas síncronas:
API Gateway → Serviço A → Serviço B → Serviço C → Serviço D
Você não tem microserviços. Você tem um sistema distribuído com single point of failure em 4 lugares diferentes.
A latência é somada. A disponibilidade é multiplicada (no sentido ruim):
Se cada serviço tem 99% de uptime: 0.99 × 0.99 × 0.99 × 0.99 = 96% de uptime totalVocê perdeu 3% de disponibilidade só pela arquitetura.
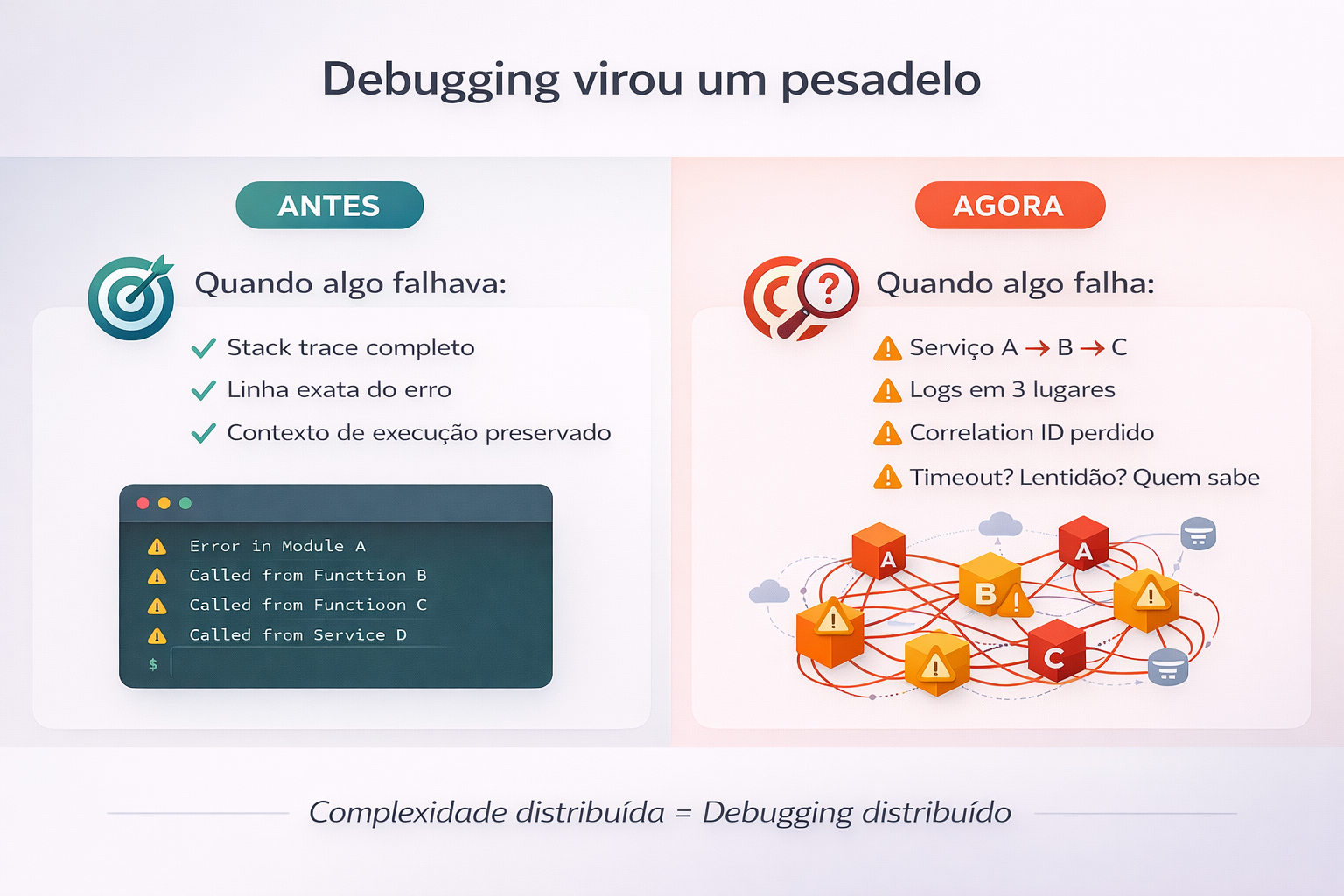
3. Não investir em observabilidade desde o início
Sem observabilidade adequada, microserviços são uma caixa preta distribuída.
Você precisa, no mínimo:
- Logging centralizado (ELK, Seq, Application Insights)
- Distributed tracing (correlation IDs, OpenTelemetry)
- Métricas de negócio e infraestrutura
- Healthchecks em todos os serviços
Se você não tem isso antes de dividir o sistema, você está criando um monstro que não conseguirá debugar.
4. Ignorar o teorema CAP e consistência eventual
Times acreditam que podem ter:
- Consistência forte
- Disponibilidade total
- Tolerância a partições de rede
Mas o teorema CAP é claro: escolha dois.
Em sistemas distribuídos, partições de rede vão acontecer.
Então você precisa escolher entre consistência e disponibilidade.
A maioria dos sistemas de microserviços precisa aceitar consistência eventual.
Mas times não planejam pra isso. Eles implementam transações distribuídas síncronas, que são:
- Lentas
- Frágeis
- Complexas
E quando falham, geram inconsistências que ninguém sabe como resolver.
5. Copiar a arquitetura da Netflix sem ter os problemas da Netflix
Quando usar microserviços vs quando evitar
✅ Microserviços fazem sentido quando:
1. Você tem times autônomos
- Cada time é dono de um contexto de negócio completo
- Times podem deployar independentemente
- Não há necessidade de coordenação constante entre times
2. Você tem escala justificável
- Partes do sistema precisam escalar de forma diferente
- Exemplo: serviço de pagamento recebe 10x mais carga que serviço de relatórios
3. Você tem contextos de negócio bem definidos
- Bounded contexts claros no DDD
- Cada serviço tem responsabilidades distintas
- Comunicação entre contextos é bem definida e limitada
4. Você aceita complexidade operacional
- Time preparado pra lidar com sistemas distribuídos
- Infraestrutura de observabilidade robusta
- Cultura de DevOps/SRE madura
❌ Microserviços NÃO fazem sentido quando:
1. Você tem um time pequeno
Se você tem 1-2 times, monólito modular é mais produtivo.
2. Você não tem maturidade operacional
Se você ainda está aprendendo a fazer deploy de forma confiável, não adicione a complexidade de coordenar 10 deploys diferentes.
3. Seus contextos de negócio são acoplados
Se toda feature precisa mexer em 4 serviços, você não tem autonomia. Tem um monólito distribuído.
4. Você não tem ferramentas adequadas
Sem observabilidade, CI/CD automatizado e infraestrutura como código, microserviços são um tiro no pé.
Sinais de que microserviços viraram problema:
- Deploy virou mais lento e arriscado que antes
- Desenvolvimento local requer subir 10+ serviços
- Debugging leva horas pra achar onde está o problema
- Mudanças simples precisam de coordenação entre múltiplos times
- Dados inconsistentes entre serviços são comuns
- Latência aumentou significativamente
- Downtime aumentou em vez de diminuir
Se você tem 3 ou mais desses sintomas, você não tem microserviços.
Você tem um monólito distribuído.
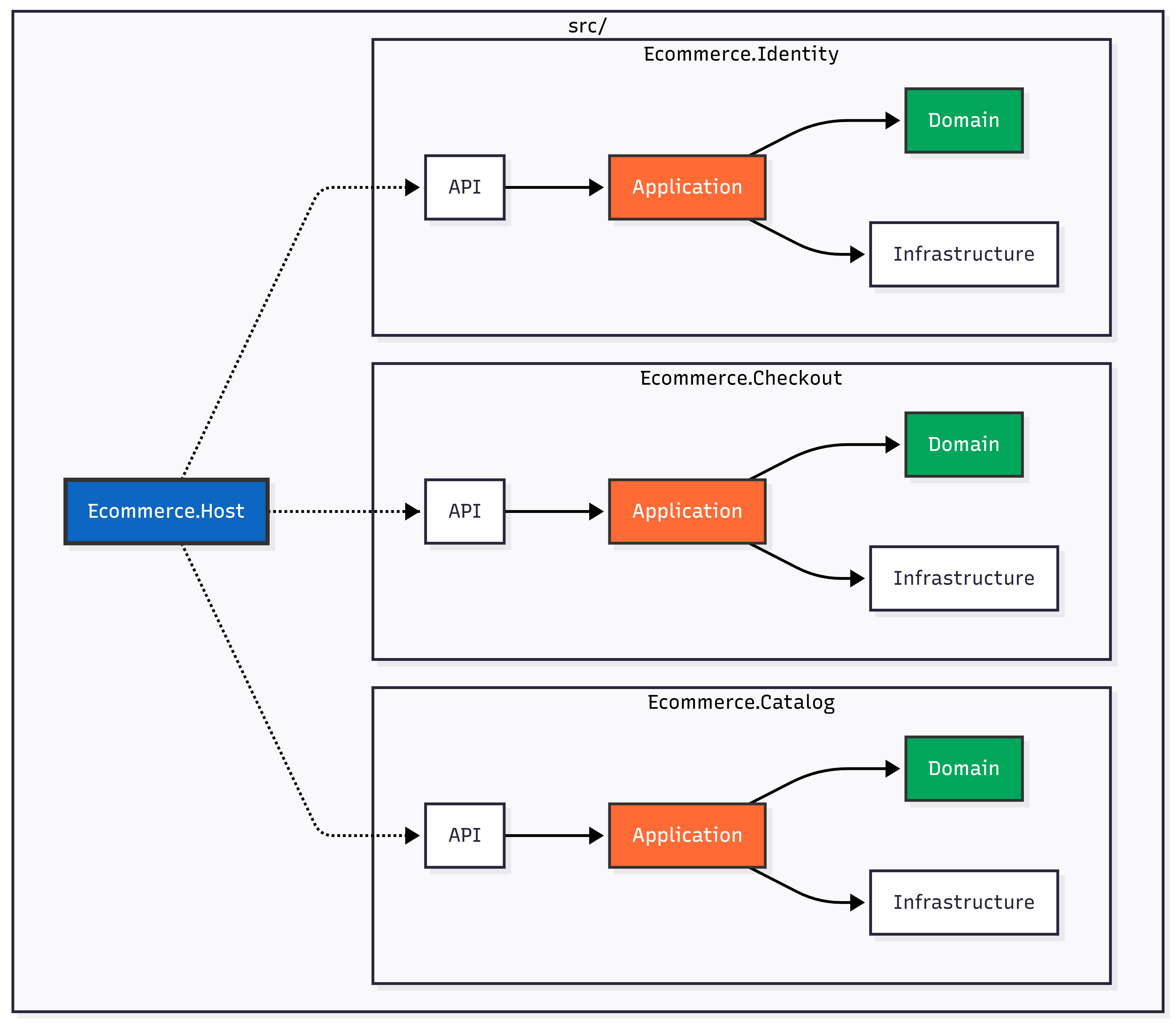
Demonstração técnica: o caminho do meio
Antes de ir pra microserviços: modular o monólito
Se você tem um monólito acoplado, não pule direto pra microserviços.
Primeiro, module o monólito.
Exemplo de estrutura modular em .NET:
Cada módulo é independente, mas ainda roda no mesmo processo.
Vantagens:
- Boundaries claros entre contextos
- Deploy ainda é simples (um único artefato)
- Debugging ainda funciona
- Transações ACID ainda funcionam
- Refatoração entre módulos é possível
- Pode virar microserviço no futuro (se necessário)
Quando partir pra microserviços: comunicação via eventos
Se você realmente precisa de microserviços, evite chamadas síncronas.
Use eventos e mensageria:
// Serviço de Checkout
public class CheckoutService
{
private readonly IEventBus _eventBus; public async Task<Result> FinalizarPedido(int pedidoId)
{
var pedido = await _pedidoRepository.GetById(pedidoId); // Valida e finaliza o pedido localmente
pedido.Finalizar();
await _pedidoRepository.Update(pedido); // Publica evento para outros serviços reagirem
await _eventBus.Publish(new PedidoFinalizadoEvent
{
PedidoId = pedido.Id,
ClienteId = pedido.ClienteId,
ValorTotal = pedido.ValorTotal,
DataFinalizacao = pedido.DataFinalizacao
}); return Result.Ok();
}
}// Serviço de Notificações (outro serviço, outro processo)
public class PedidoFinalizadoHandler : IEventHandler<PedidoFinalizadoEvent>
{
public async Task Handle(PedidoFinalizadoEvent evento)
{
// Busca dados do cliente localmente (dados replicados)
var cliente = await _clienteRepository.GetById(evento.ClienteId); // Envia notificação
await _emailService.EnviarConfirmacaoPedido(cliente.Email, evento.PedidoId);
}
}
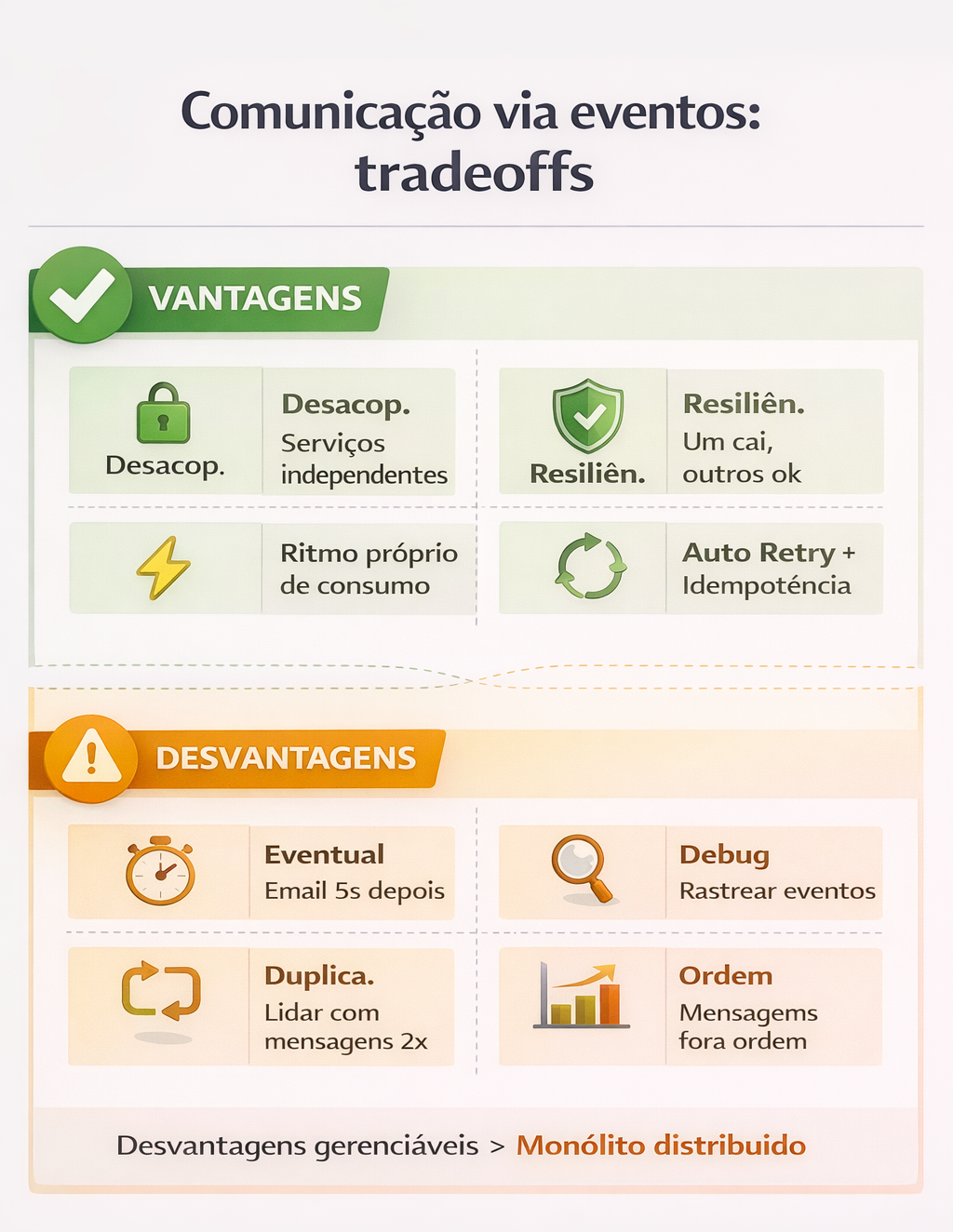
Vantagens:
- Serviços desacoplados
- Se o serviço de Notificações cair, o checkout continua funcionando
- Cada serviço consome eventos no seu próprio ritmo
- Retry e idempotência são gerenciados pela infraestrutura de mensageria
Desvantagens:
- Consistência eventual (o email pode chegar 5 segundos depois)
- Debugging mais complexo (precisa rastrear eventos)
- Precisa lidar com mensagens duplicadas/fora de ordem
Mas essas desvantagens são gerenciáveis.
Já um monólito distribuído com chamadas síncronas não é.
Impactos invisíveis: o custo que ninguém mede
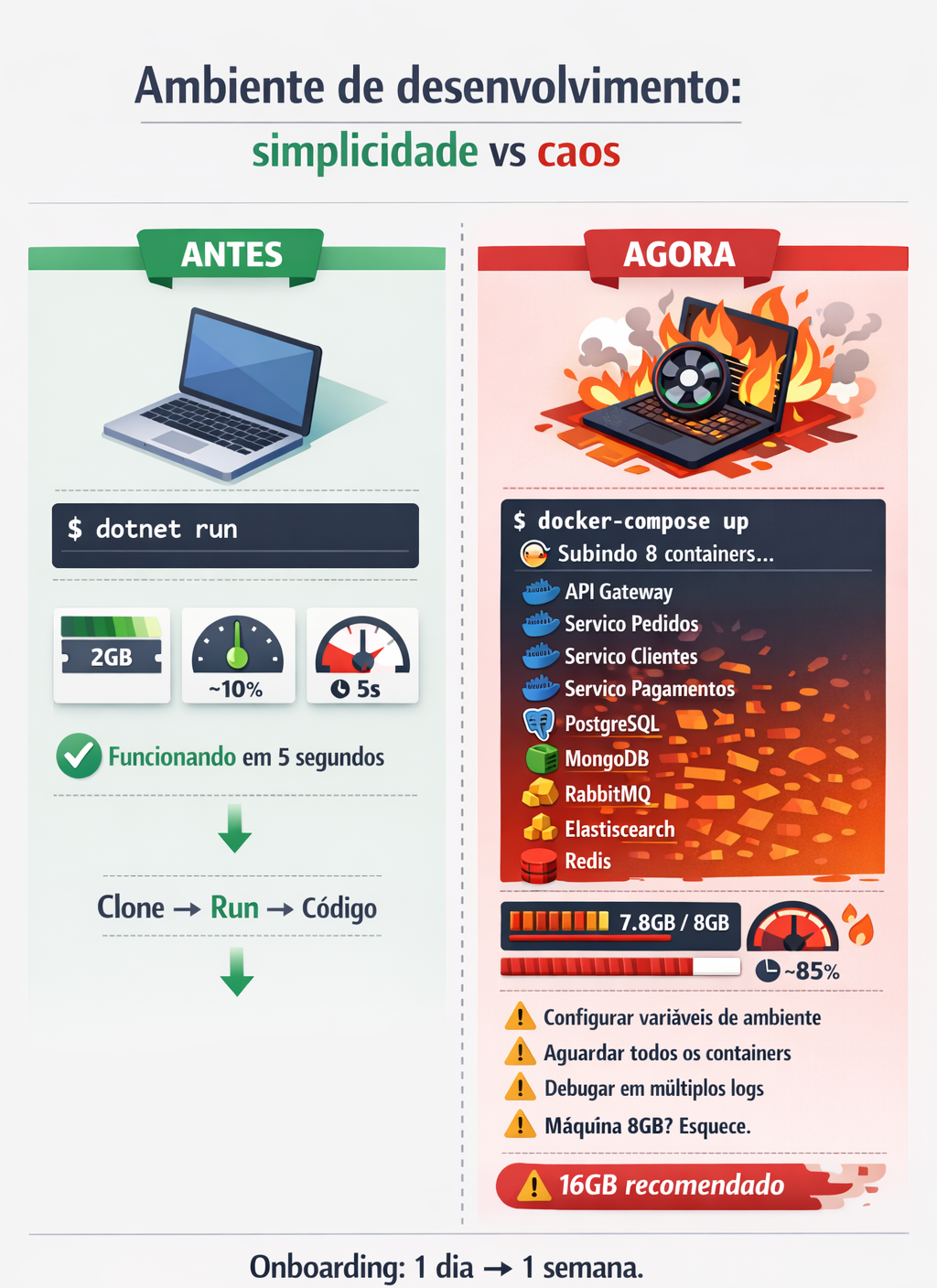
1. Onboarding de novos desenvolvedores
Monólito:
- Clone o repositório
- Rode
dotnet run - Pronto
Monólito distribuído:
- Clone 8 repositórios
- Configure variáveis de ambiente em cada um
- Suba Docker Compose com 10 containers
- Aguarde 5 minutos
- Descubra que faltou configurar o RabbitMQ
- Descubra que sua máquina não aguenta rodar tudo
- Desista e peça acesso ao ambiente de dev compartilhado
Custo: 1 dia vira 1 semana. Novos devs levam um mês pra se sentir produtivos.
2. Autonomia do time
Objetivo dos microserviços: times autônomos, deploys independentes.
Realidade do monólito distribuído:
- Precisa coordenar deploy com 3 outros times
- Breaking changes precisam ser negociados
- Versionamento de APIs vira um pesadelo
- "Independence day" vira "dependency hell"
Custo: reuniões intermináveis pra coordenar releases.
3. Lead time
Monólito bem arquitetado:
- Feature implementada: 2 dias
- Code review: 1 dia
- Deploy: 30 minutos
- Total: 3-4 dias
Monólito distribuído:
- Feature implementada em 3 serviços: 3 dias
- 3 PRs pra revisar: 2 dias
- Coordenar deploy dos 3 serviços: 1 dia
- Descobrir que quebrou em produção: 2 horas
- Rollback coordenado: 1 hora
- Descobrir qual serviço está causando o problema: 3 horas
- Fix e re-deploy: 1 dia
- Total: 7-8 dias
Custo: features levam 2x mais tempo pra chegar em produção.
4. Qualidade de decisão
Em monólitos distribuídos, decisões técnicas são tomadas por limitação, não por escolha consciente:
- "Vamos duplicar esses dados porque não dá pra chamar o outro serviço"
- "Vamos fazer cache agressivo porque a latência tá alta"
- "Vamos aceitar inconsistência porque não tem como garantir transação"
Cada decisão dessas adiciona débito técnico.
Após 1 ano, ninguém mais sabe por que as coisas são assim.
Só sabe que "é assim que funciona".
A raiz do problema: decisão técnica sem fundamento organizacional
O maior erro ao adotar microserviços é tratar como decisão puramente técnica.
Microserviços não são sobre Docker, Kubernetes ou API Gateway.
São sobre autonomia de times, ownership claro e contexts bem delimitados.
Se você não tem:
- Times com ownership claro de cada contexto
- Cultura de DevOps (cada time cuida do próprio deploy e operação)
- Bounded contexts bem definidos (DDD)
- Tolerância a consistência eventual
Você não está pronto pra microserviços.
E não tem problema nisso.
Monólitos bem arquitetados são subestimados.
Empresas como Shopify, GitHub e Stack Overflow rodam monólitos que servem milhões de usuários.
O segredo não é a arquitetura. É a disciplina.
Quando revisitar a decisão
Microserviços podem ser a resposta certa. Mas precisam ser revisitados constantemente:
Perguntas que todo time deveria fazer a cada 6 meses:
- Os serviços realmente são independentes?
- Ou precisamos deployar vários ao mesmo tempo?
- A comunicação é assíncrona ou síncrona?
- Chamadas HTTP síncronas entre serviços são um red flag
- Temos observabilidade adequada?
- Conseguimos debugar problemas em produção?
- O desenvolvimento local é produtivo?
- Ou os devs estão desistindo e usando ambientes compartilhados?
- Os times são autônomos?
- Ou precisam de coordenação constante?
- A latência é aceitável?
- Ou está crescendo de forma descontrolada?
- Dados estão consistentes?
- Ou temos sincronização manual e inconsistências frequentes?
Se as respostas forem negativas, você tem um problema de arquitetura, não de implementação.
E a solução pode não ser "fazer microserviços melhor".
Pode ser voltar atrás e consolidar em um monólito modular.
E não tem problema nisso.
Arquitetura não é sobre orgulho. É sobre resolver problemas de verdade.
Alternativas antes de microserviços
1. Monólito modular
Um único deploy, mas com módulos bem delimitados.
- Módulos independentes - Comunicação via interfaces internas - Transações ACID funcionam - Deploy simples - Debugging simples - Pode se tornar microserviços no futuro (se necessário)
Quando usar: 90% dos casos.
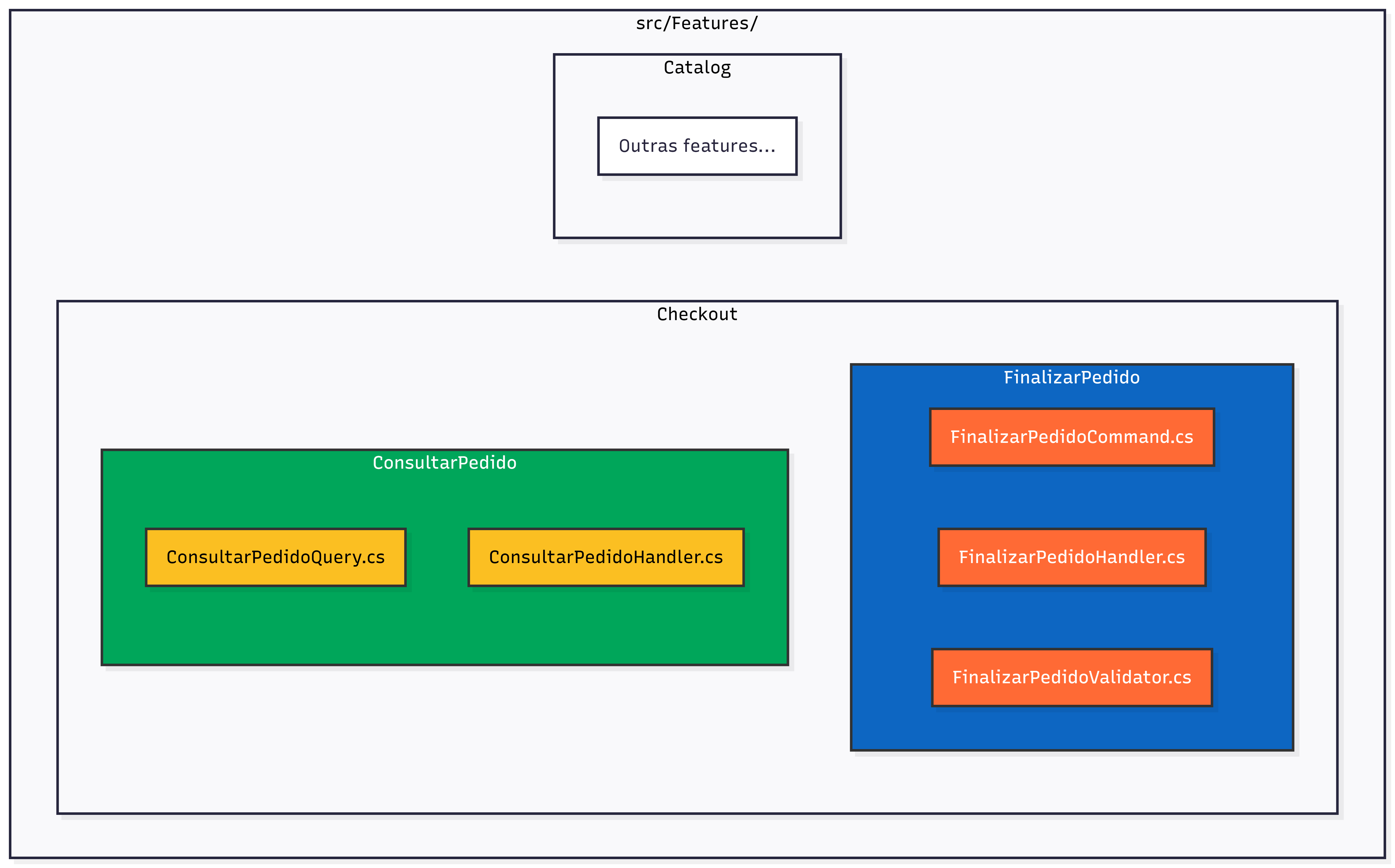
2. Monólito modular com vertical slices
Arquitetura de fatias verticais (Vertical Slice Architecture) + CQRS seletivo.
Cada feature é uma fatia completa do sistema (API → Lógica → Dados).
Cada fatia é isolada e testável.
Ainda é um monólito, mas com boundaries claros.
3. Microserviços bem feitos
Se você realmente precisa de microserviços:
- Bounded contexts claros (DDD)
- Comunicação via eventos (assíncrona)
- Cada serviço tem seus próprios dados (sem chamadas síncronas pra buscar dados)
- Observabilidade desde o dia 1
- Times com ownership claro de cada serviço
- CI/CD robusto pra cada serviço
Conclusão: maturidade é saber quando não fazer
Microserviços são uma ferramenta poderosa.
Mas como toda ferramenta poderosa, pode causar mais dano que benefício quando mal utilizada.
O problema não é a arquitetura. É a falta de contexto.
Times adotam microserviços porque:
- "É o que empresas modernas fazem"
- "Vai resolver nossos problemas de escalabilidade"
- "Monólitos são legado"
Mas ignoram que:
- Netflix tem mais milhares de engenheiros
- Amazon tem contextos de negócio completamente isolados
- Google tem décadas de experiência com sistemas distribuídos
Se você tem 1 time de 8 pessoas, você não tem os mesmos problemas.
Logo, não precisa das mesmas soluções.
Maturidade técnica não é adotar a tecnologia mais nova.
É escolher a arquitetura certa pro problema certo no momento certo.
E ter a humildade de revisitar essa decisão quando o contexto mudar.
Monólitos bem arquitetados não são vergonha.
Microserviços mal implementados, sim.
Decisões técnicas não falham sozinhas. Elas falham quando deixam de ser revisitadas.
Em times que crescem, maturidade técnica não vem de mais padrões, mas da capacidade de questionar os que já existem.
Se esse tipo de reflexão faz sentido para você, conecte-se comigo no LinkedIn: https://www.linkedin.com/in/felipe-santos-marciano/
Instagram: https://www.instagram.com/felipemarcianodev/
Youtube: https://www.youtube.com/@felipemarcianodev